1. 프로젝트 소개 및 개요
이화여대 컴퓨터공학과 [캡스톤 디자인 및 창업 프로젝트 B] 수업의 졸업프로젝트로,
우리 팀은 Once(원스) 애플리케이션을 고안하고 개발하게 되었다.
Once 프로젝트 소개
카드 다보유자를 위한 결제 전 최대 할인 카드를 추천해주는 AI 챗봇 서비스
원스는 카드 다보유자를 위해, 결제 전 결제처와 결제 금액을 입력하면
사용자가 보유한 카드 중 해당 결제처에서 가장 할인 금액이 높은 카드를 추천해주는 핀테크 모바일 애플리케이션이다.

Tech Stack
Once 의 주요 SW 모듈 및 SW Architecture 구조는 다음과 같다.
1) Front-End : Flutter (Dart)
2) Back-End
- 프레임워크 : SpringBoot (Java)
- 클라우드 호스팅 : AWS - EC2, RDS(MySQL), S3
- 크롤링 라이브러리 : BeatifulSoup, Selenium
- 인공지능 카드 추천 모델 : OpenAI GPT-3.5 Turbo Fine-Tuning
3) 외부 오픈 소스
- Docker
- CODEF API : 사용자 보유 카드 목록, 실적 충족 여부, 카드 승인 내역 API 조회
Once 프로젝트에서 크롤링, Front-End 개발, Back-End API 개발을 맡아 진행하였다.
각각의 기술 스택에 대해 아래에 상세히 기술하였다.
2. 삼성 카드/현대 카드 혜택 크롤링
소비자와 카드사 간의 정보 비대칭 문제를 해결하기 위해서는,
주기적인 크롤링을 통해 소비자에게 최신 혜택 정보를 제공하는 것이 중요하다고 생각했기에,
개발의 첫 시작으로 카드 혜택 크롤링을 진행하게 되었다.
우리 팀은 [ 신한, 국민, 삼성, 롯데, 하나, 현대 ] 6개 카드사의 크롤링을 진행하였는데,
그 중 삼성카드와 현대카드 혜택 크롤링을 맡게 되었다.
크롤링 하는 방법을 한번 터득하고 나면, 크롤링 코드를 작성하는 것이 크게 어렵지 않은데,
처음 크롤링을 시작했을때 어디부터 어떻게 시작해야 할지 애를 먹었던 기억이 있어서,,,😂
크롤링 방법을 단계별로 자세하게 작성해보려고 한다.
(삼성카드를 기준으로 작성했으나, 현대카드도 동일한 방식으로 개발하였다.)
1. 카드 리스트 수집
먼저 각 카드의 상세 페이지에 자동으로 접근하게 하기 위해서는,
카드 리스트 페이지에서 각 카드의 이름, 이미지, 상세 페이지 URL을 수집하는 과정이 필요하다.
(수동으로 카드 리스트를 수집하게 되면, 카드가 추가되거나 변경되었을 때 매번 수동으로 업데이트 해주어야 하므로,
카드 리스트 페이지를 크롤링하는 방식이 좋다.)
삼성 카드의 경우 아래의 리스트 페이지에서, 전체 삼성 카드 리스트를 추출하였다.
https://www.samsungcard.com/home/card/cardinfo/PGHPPDCCardCardinfoRecommendPC001
추천 카드안내_삼성카드
모니모카드 요즘 감성, 요즘 혜택
www.samsungcard.com
이때 Once 앱의 경우 카드가 신용카드인지, 체크카드인지 여부를 ERD 칼럼에 작성해야 했기 때문에,
신용카드 크롤링 코드는 credit.py 파일에, 체크카드 크롤링 코드는 debit.py 코드에 작성하였다.
[ 삼성 신용카드 리스트 추출 - credit.py ]
IDE는 Visual Studio Code를 사용하여 진행하였다.
먼저 크롤링을 위해 BeautifulSoup와 Selenium 라이브러리를 이용하기 위해,
터미널에서 아래의 install 명령어를 실행한다.
pip install bs4
pip install selenium
이후 카드사 홈페이지에서 개발자 도구를 켜면 (Window - F12버튼)
아래와 같이 해당 페이지의 HTML 코드를 확인할 수 있다.
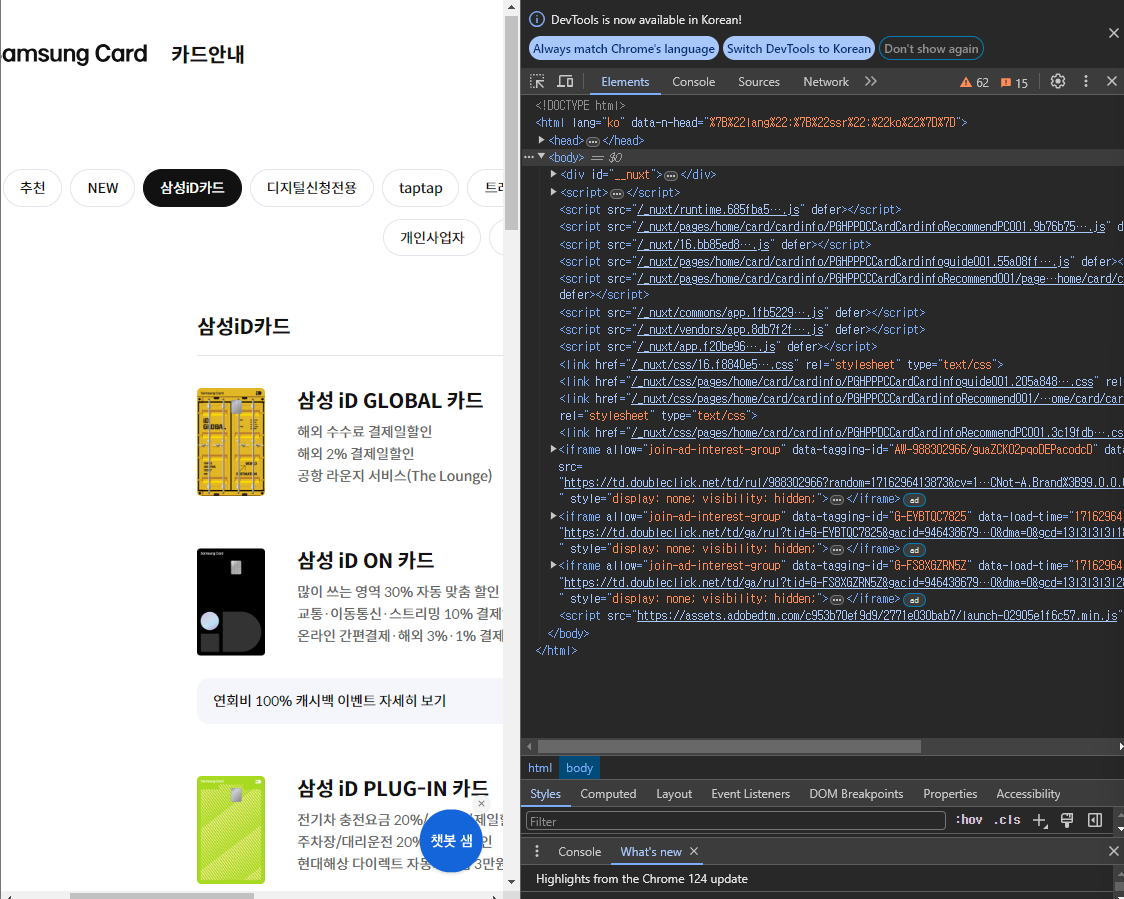
크롤링 과정에서 중간 중간 개발자 도구가 몇 초 후에 자동으로 꺼지는 현상이 발생했는데,
찾아보니 보안 프로그램(아마도 알약...?)으로 인해 발생되는 오류인 것 같다.
해당 보안 프로그램의 설정을 변경하는 방식도 있었는데,
단순히 Microsoft Edge 브라우저를 이용하였더니, 해당 문제가 더 이상 발생하지 않아 그대로 진행하였다.
카드 이름은 card_names에, 상세 페이지 url은 card_urls에, 이미지는 card_imgs 리스트에 넣도록
코드를 작성하였다.
이때 html 코드에서 카드 이름, url, 이미지 정보가 들어가 있는 tab 이름은 통일 되어 있으므로,
한 카드의 이름, url, 이미지 tab 정보만 알아낸다면,
단순히 for문을 이용해서 모든 카드의 리스트를 수집할 수 있다.
한 카드의 html tab 정보를 알아내기 위해서는,
개발자 도구에서 F12(검색)를 실행한 후, 찾고자 하는 정보(ex. 삼성 iD GLOBAL 카드)를 입력하면
해당 정보가 어느 탭에 속해 있는지 확인할 수 있다.

해당 삼성 신용 카드의 경우,
카드 이름은 div tab의 class 이름이 'tit-04' 부분에,
카드 이미지는 img tab의 src 부분에,
카드 url은 이미지 src의 끝에서 11번째 ~ 4번째 값의 코드를
'https://www.samsungcard.com/home/card/cardinfo/PGHPPCCCardCardinfoDetails001?code='
해당 url 뒷 부분에 덧붙이는 구조로 이루어져 있는 것을 확인할 수 있다.
url 형식 : https://www.samsungcard.com/home/card/cardinfo/PGHPPCCCardCardinfoDetails001?code=[카드별 고유 번호]
해당 카드들은 lists 클래스의 ul 태그 안의 li 태그에 속해 있으므로,
해당 li 태그를 for문으로 순차 탐색하는 아래의 코드를 작성해주면 삼성 신용카드 리스트가 반환되는 것을 확인할 수 있다.
전체 코드는 다음과 같다.
import pandas as pd
import time
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup
'''
신용 카드 리스트 조회
samsung_creditcardInfos.csv : card_name, card_url, card_img
'''
url = "https://www.samsungcard.com/home/card/cardinfo/PGHPPDCCardCardinfoRecommendPC001"
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-web-security')
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
driver.implicitly_wait(20)
print("======= [삼성] 신용 카드 리스트 크롤링 =======")
print("웹 페이지에 접속 중...")
driver.get(url)
time.sleep(3)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
card_names = []
card_urls = []
card_imgs = []
card_tab_section = soup.find_all('div', class_='tab-section')
for i in range(2, len(card_tab_section)):
ul_tag = card_tab_section[i].find('ul', class_='lists')
list_elements = ul_tag.find_all('li')
for idx, element in enumerate(list_elements, 1):
card_name_element = element.find('div', class_='tit-h4')
card_names.append(card_name_element.text.strip())
card_img_element = element.find('img').get('src')
card_imgs.append(card_img_element)
card_url_code = card_img_element[-11:-4]
card_urls.append('https://www.samsungcard.com/home/card/cardinfo/PGHPPCCCardCardinfoDetails001?code=' + card_url_code)
print("작업을 완료했습니다.")
driver.quit()
# 중복 제거
unique_card_urls = list(set(card_urls))
data = {"card_name": [], "card_url": [], "card_img": []}
# 중복 제거된 card_url에 해당하는 정보만 데이터에 추가
for url in unique_card_urls:
index = card_urls.index(url)
data["card_name"].append(card_names[index])
data["card_url"].append(card_urls[index])
data["card_img"].append(card_imgs[index])
df = pd.DataFrame(data)
df.to_csv("./samsung_creditcardInfos.csv", encoding = "utf-8-sig")
이때 pandas를 이용하여 해당 정보를 samsung_creditcardInfos.csv 파일에 저장하도록 하였으므로,
해당 파일을 열어보면 카드 리스트가 올바르게 추출된 것을 확인할 수 있다.

[ 삼성 체크카드 리스트 추출 ]
체크카드도 동일한 방식으로 리스트를 추출해주었다.
체크카드 크롤링 코드 및 결과 csv 파일은 다음과 같다.
(체크카드 리스트는 비교적 적어서 수월했다..ㅎㅎ😊)
import pandas as pd
import time
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup
'''
체크 카드 리스트 조회
samsung_checkcardInfos.csv : card_name, card_url, card_img
'''
url = "https://www.samsungcard.com/home/card/cardinfo/PGHPPCCCardCardinfoCheckcard001"
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-web-security')
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
driver.implicitly_wait(20)
print("======= [삼성] 체크 카드 리스트 크롤링 =======")
print("웹 페이지에 접속 중...")
driver.get(url)
time.sleep(3)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
card_names = []
card_urls = []
card_imgs = []
ul_tag = soup.find('ul', class_='lists')
list_elements = ul_tag.find_all('li')
for idx, element in enumerate(list_elements, 1):
card_name_element = element.find('div', class_='tit-h4')
card_names.append(card_name_element.text.strip())
card_img_element = element.find('img').get('src')
card_imgs.append(card_img_element)
card_url_code = card_img_element[-8:-4]
card_urls.append('https://www.samsungcard.com/home/card/cardinfo/PGHPPCCCardCardinfoDetails001?code=ABP' + card_url_code)
print("작업을 완료했습니다.")
driver.quit()
data = {"card_name" : card_names, "card_url" : card_urls, "card_img": card_imgs}
df = pd.DataFrame(data)
df.to_csv("./samsung_checkcardInfos.csv", encoding = "utf-8-sig")

2. 각 카드 혜택 데이터 수집
앞서 수집한 카드 리스트를 바탕으로 각 카드의 혜택 데이터를 수집해보자.
[ 삼성 신용카드 카드별 상세 혜택 추출 ]
앞서 리스트에서 추출한 각 카드 페이지 url을
for 문을 통해 차례대로 방문하며 카드 혜택 정보를 추출하면 된다.
똑같이 개발자 도구(F12)를 켠 후, 검색 기능을 통해 추출하고자 하는 정보를 검색한 후,
해당 내용이 html의 어느 태그에 들어가 있는지 확인하면 된다.
이때, 삼성 카드의 경우 dot-title이 ["요약", "카드이용TIP", "카드 디자인 소개", "네이버 디지털콘텐츠 적립 혜택 적용방법", "신세계포인트 적립 서비스", "세무지원 서비스", "BIZ SERVICE", "SPECIAL PLATE", "신세계백화점 제휴 서비스"]
에 해당되는 경우, 카드 혜택이 아닌 카드 부가 서비스에 대한 상세 기능만 서술되어 있었으므로,
해당 타이틀이 있는 경우에는 혜택 내용을 추출하지 않도록 코드를 작성하였다.
전체 코드는 아래와 같다.
import pandas as pd
import time
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup
'''
신용 카드 리스트 조회
samsung_creditcardInfos.csv : card_name, card_url, card_img
'''
url = "https://www.samsungcard.com/home/card/cardinfo/PGHPPDCCardCardinfoRecommendPC001"
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-web-security')
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
driver.implicitly_wait(20)
print("======= [삼성] 신용 카드 리스트 크롤링 =======")
print("웹 페이지에 접속 중...")
driver.get(url)
time.sleep(3)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
card_names = []
card_urls = []
card_imgs = []
card_tab_section = soup.find_all('div', class_='tab-section')
for i in range(2, len(card_tab_section)):
ul_tag = card_tab_section[i].find('ul', class_='lists')
list_elements = ul_tag.find_all('li')
for idx, element in enumerate(list_elements, 1):
card_name_element = element.find('div', class_='tit-h4')
card_names.append(card_name_element.text.strip())
card_img_element = element.find('img').get('src')
card_imgs.append(card_img_element)
card_url_code = card_img_element[-11:-4]
card_urls.append('https://www.samsungcard.com/home/card/cardinfo/PGHPPCCCardCardinfoDetails001?code=' + card_url_code)
print("작업을 완료했습니다.")
driver.quit()
# 중복 제거
unique_card_urls = list(set(card_urls))
data = {"card_name": [], "card_url": [], "card_img": []}
# 중복 제거된 card_url에 해당하는 정보만 데이터에 추가
for url in unique_card_urls:
index = card_urls.index(url)
data["card_name"].append(card_names[index])
data["card_url"].append(card_urls[index])
data["card_img"].append(card_imgs[index])
df = pd.DataFrame(data)
df.to_csv("./samsung_creditcardInfos.csv", encoding = "utf-8-sig")
'''
신용 카드 혜택 크롤링
credit_benefit.csv : card_company_id, name, img_url, benefits, created_at, type
'''
card_infos = pd.read_csv('./samsung_creditcardInfos.csv')
card_urls = card_infos['card_url'].tolist()
name = card_infos['card_name'].tolist()
img_url = card_infos['card_img'].tolist()
card_company_id = [3] * len(card_urls)
benefits = []
created_at = []
type = ["CreditCard"] * len(card_urls)
print("======= [삼성] 전체 카드 혜택 정보 크롤링 =======")
for i in range(len(card_urls)):
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-web-security')
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
driver.implicitly_wait(20)
now = datetime.now()
created_at.append(now)
print(f"{now} [{card_names[i]}] --- 웹 페이지에 접속 중... ({i+1}/{len(card_urls)})")
driver.get(card_urls[i])
time.sleep(3)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# 상세 혜택 =============================================
tab_container = soup.find('section', class_='tab-container')
tab_list = tab_container.find_all('div', role='tabpanel')
benefit_title = []
benefit = ''
for i in range(len(tab_list)):
tab_name = tab_list[i].find('div', class_='dot-title').text.strip()
if tab_name not in ["요약", "카드이용TIP", "카드 디자인 소개", "네이버 디지털콘텐츠 적립 혜택 적용방법", "신세계포인트 적립 서비스", "세무지원 서비스", "BIZ SERVICE", "SPECIAL PLATE", "신세계백화점 제휴 서비스"]:
benefit_title.append(tab_name)
for i in range(len(tab_list)):
tab_name = tab_list[i].find('div', class_='dot-title').text.strip()
if tab_name in ["요약", "카드이용TIP", "카드 디자인 소개", "네이버 디지털콘텐츠 적립 혜택 적용방법", "신세계포인트 적립 서비스", "세무지원 서비스", "BIZ SERVICE", "SPECIAL PLATE", "신세계백화점 제휴 서비스"]:
continue
j = 0
benefit += f'###{benefit_title[j]}'
j += 1
benefit_list = tab_list[i].find_all('h5', class_='tit04')
for title in benefit_list:
if (title.text.strip() == "유의사항") or (title.text.strip() == "국제 브랜드사 서비스 공통 유의사항"):
break
benefit += f'[{title.text.strip()}]'
next_sibling = title.find_next_sibling()
if next_sibling is not None and next_sibling.name == 'div' and 'table_col' in next_sibling.get('class', []):
table = next_sibling.select_one('table')
if table:
rows = table.find_all('tr')
for j, row in enumerate(rows):
cells = row.find_all(['th', 'td'])
row_data = ['(' + cell.text.strip() + ')' for cell in cells]
row_string = ' '.join(row_data)
sentence = f"표의 {j + 1}번째 행은 {row_string}로 이루어져 있습니다."
benefit += sentence
elif next_sibling is not None and next_sibling.name == 'ul':
benefit += next_sibling.text.strip()
benefits.append(benefit)
print("작업을 완료했습니다.")
driver.quit()
'''
신용 카드 혜택 크롤링
credit_benefit.csv : card_company_id, name, img_url, benefits, created_at, type
'''
data = {"card_company_id": card_company_id, "name": name, "img_url": img_url, "benefits" : benefits, "created_at": created_at, "type": type}
df = pd.DataFrame(data)
df.to_csv("./credit_benefit.csv", encoding = "utf-8-sig", index=False)
크롤링된 혜택 정보를 credit_benefit.csv 파일에 저장하도록 작성했으므로, 해당 파일을 확인해보면,
아래 사진과 같이 모든 카드 리스트의 혜택 정보가 올바르게 추출된 것을 확인할 수 있다.

다만 새로운 카드가 추가되었을 때,
해당 카드에 혜택이 아닌 내용이 작성되어 있는데, 위의 dot-title에 해당되지 않는 경우,
매번 새롭게 예외처리를 해줄 수 없다는 문제점이 있었다..
해당 부분을 처리할 마땅한 방법이 떠오르지 않아, 일단 위의 방식으로 필요 없는 부분은 잘라내도록 코드를 작성하였는데,
더 효율적이고 자동화 할 수 있는 코드를 작성하는 방법을 고민해봐야겠다!
[ 삼성 체크카드 카드별 상세 혜택 추출 ]
체크카드 역시 동일한 방식으로 코드를 작성하였다.
체크카드 혜택 추출 코드 및 결과 csv 파일은 다음과 같다.
import pandas as pd
import time
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup
'''
체크 카드 리스트 조회
samsung_checkcardInfos.csv : card_name, card_url, card_img
'''
url = "https://www.samsungcard.com/home/card/cardinfo/PGHPPCCCardCardinfoCheckcard001"
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-web-security')
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
driver.implicitly_wait(20)
print("======= [삼성] 체크 카드 리스트 크롤링 =======")
print("웹 페이지에 접속 중...")
driver.get(url)
time.sleep(3)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
card_names = []
card_urls = []
card_imgs = []
ul_tag = soup.find('ul', class_='lists')
list_elements = ul_tag.find_all('li')
for idx, element in enumerate(list_elements, 1):
card_name_element = element.find('div', class_='tit-h4')
card_names.append(card_name_element.text.strip())
card_img_element = element.find('img').get('src')
card_imgs.append(card_img_element)
card_url_code = card_img_element[-8:-4]
card_urls.append('https://www.samsungcard.com/home/card/cardinfo/PGHPPCCCardCardinfoDetails001?code=ABP' + card_url_code)
print("작업을 완료했습니다.")
driver.quit()
data = {"card_name" : card_names, "card_url" : card_urls, "card_img": card_imgs}
df = pd.DataFrame(data)
df.to_csv("./samsung_checkcardInfos.csv", encoding = "utf-8-sig")
'''
체크 카드 혜택 크롤링
debit_benefit.csv : card_company_id, name, img_url, benefits, created_at, type
'''
card_infos = pd.read_csv('./samsung_checkcardInfos.csv')
card_urls = card_infos['card_url'].tolist()
name = card_infos['card_name'].tolist()
img_url = card_infos['card_img'].tolist()
card_company_id = [3] * len(card_urls)
benefits = []
created_at = []
type = ["DebitCard"] * len(card_urls)
print("======= [삼성] 전체 카드 혜택 정보 크롤링 =======")
for i in range(len(card_urls)):
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-web-security')
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
driver.implicitly_wait(20)
now = datetime.now()
created_at.append(now)
print(f"{now} [{card_names[i]}] --- 웹 페이지에 접속 중... ({i+1}/{len(card_urls)})")
driver.get(card_urls[i])
print(card_urls[i])
time.sleep(3)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# 상세 혜택 =============================================
tab_container = soup.find('section', class_='tab-container')
tab_list = tab_container.find_all('div', class_='tab-section')
benefit_title = []
benefit = ''
print(i)
for i in range(1, len(tab_list)):
benefit_title.append(tab_list[i].find('div', class_='dot-title').text.strip())
for i in range(1, len(tab_list)):
benefit += f'###{benefit_title[i-1]}'
benefit_list = tab_list[i].find_all('h5', class_='tit04')
for title in benefit_list:
if (title.text.strip() == "유의사항") or (title.text.strip() == "문의"):
break
benefit += f'[{title.text.strip()}]'
next_sibling = title.find_next_sibling()
if next_sibling.name == 'div' and 'table_col' in next_sibling.get('class', []):
table = next_sibling.select_one('table')
if table:
rows = table.find_all('tr')
for j, row in enumerate(rows):
cells = row.find_all(['th', 'td'])
row_data = ['(' + cell.text.strip() + ')' for cell in cells]
row_string = ' '.join(row_data)
sentence = f"표의 {j + 1}번째 행은 {row_string}로 이루어져 있습니다."
benefit += sentence
elif next_sibling.name == 'ul':
benefit += next_sibling.text.strip()
benefits.append(benefit)
print("작업을 완료했습니다.")
driver.quit()
'''
체크 카드 혜택 크롤링
debit_benefit.csv : card_company_id, name, img_url, benefits, created_at, type
'''
data = {"card_company_id": card_company_id, "name": name, "img_url": img_url, "benefits" : benefits, "created_at": created_at, "type": type}
df = pd.DataFrame(data)
df.to_csv("./debit_benefit.csv", encoding = "utf-8-sig", index=False)

현대 카드 역시 삼성카드와 동일한 방식으로 크롤링을 진행하였고,
해당 크롤링 코드는 아래의 github 페이지에서 확인할 수 있다.
[ crawling github ]
https://github.com/EWHA-LUX/card-crawling
GitHub - EWHA-LUX/card-crawling
Contribute to EWHA-LUX/card-crawling development by creating an account on GitHub.
github.com
3. Front-End flutter 개발
안드로이드 및 iOS 운영체제에서 모두 실행이 가능한 크로스플랫폼으로 개발하기 위해
flutter를 이용하여 Front-End 개발을 진행하게 되었다.
우리 팀에 프론트 개발자가 없어 프론트도 함께 개발하게 되었는데,
React나 Android 개발은 간단하게 진행해본 적은 있지만,
flutter 개발은 처음이라 걱정이 많이 앞섰었다..🥲
프론트 개발을 본격적으로 들어가기 전에
유튜브 [ 개발하는 남자 - 인스타그램 클론코딩 ] 강의를 들었는데,
처음 flutter 감을 잡는데 큰 도움이 되어 소개한다!
https://www.youtube.com/watch?v=hM2whwf2u14&list=PLgRxBCVPaZ_1iBe1v3-ZSSzHGdQo7AZPq
flutter 개발이 처음이다 보니, 처음 프로젝트를 세팅하는 과정부터 난관이었다,,🫠
github flutter 프로젝트들을 찾아다니면서 공부하다가, 아래와 같이 프로젝트 세팅을 진행하게 되었다!
프로젝트 세팅 구조
먼저 flutter 프로젝트 폴더는 다음과 같이 구성하면 된다.
꼭 해당 구조대로 세팅할 필요는 없지만,
flutter 프로젝트에서 가장 많이 사용되는 방식으로 프로젝트를 세팅하였다.
ONCE-FE
│
├── assets
│ └── fonts
│ └── images
│
│ (...)
│
├── lib
│ └── src
││ ├── screens
│ │ │ └── login // 회원가입 및 로그인 관련 페이지들
│ │ │ │ └── (...)
│ │ │ │
│ │ │ └── home // 메인 챗봇 페이지들
│ │ │ │ └── home.dart
│ │ │ │ └── (...)
│ │ ││
│ │ │ └── mywallet // 마이 월렛 관련 페이지들
│ │ │ │ └── mywallet.dart
│ │ │ │ └── (...)
│ │ │ │
│ │ │ └── mypage // mypage 내부에 속하는 페이지들
│ │ │ └── mypage.dart
│ │ │ └── (...)
│ │ │
│ │ ├── models
│ │ │ └── (models 내부 파일 및 폴더)
│ │ ├── utils
│ │ │ └── (utils 내부 파일 및 폴더)
│ │ ├── controller
│ │ │ └── (controller 내부 파일 및 폴더)
│ │ └── repository
│ │ │ └── (repository 내부 파일 및 폴더)
│ │
│ │ └── app.dart
│ │
│ └── main.dart
│ └── style.dart
각 폴더에는 아래의 내용에 해당되는 파일들을 작성하여 구성하면 된다.
- assets : 리소스 폴더 (정적 이미지, 아이콘, 폰트)
- lib : flutter 개발을 위한 Dart 코드 파일 저장 (앱 로직 및 뷰 구현)
- screens : 앱 고유 화면 저장
- models : 앱 전체에서 사용할 데이터 모델 파일
- utils : 앱 전체에서 사용할 공용 비즈니스 로직 (유틸리티 함수, 클래스)
- controller : 컨트롤러 및 비즈니스 로직
- repository : 외부 데이터와 상호작용하기 위한 레포지토리 및 데이터 소스 정의
- main.dart : flutter 앱 진입점, 애플리케이션 시작 정의 및 루트 위젯 생성
- style.dart : 애플리케이션 공용 스타일 지정 (텍스트 스타일, 색상)
프로젝트 테마 설정
다음으로 figma에서 디자인한 UI를 참고하여,
프로젝트의 전체 스타일로 적용해야 하는 테마 코드를 작성해주었다.
1) 폰트 적용
assets > fonts 폴더에 Pretendard, Poppins 글꼴 ttf 파일 복사하여 적용하였다.

이후 pubspec.yaml 파일 fonts 하위에 해당 폰트를 등록한 후,
pubget 을 실행해준다.
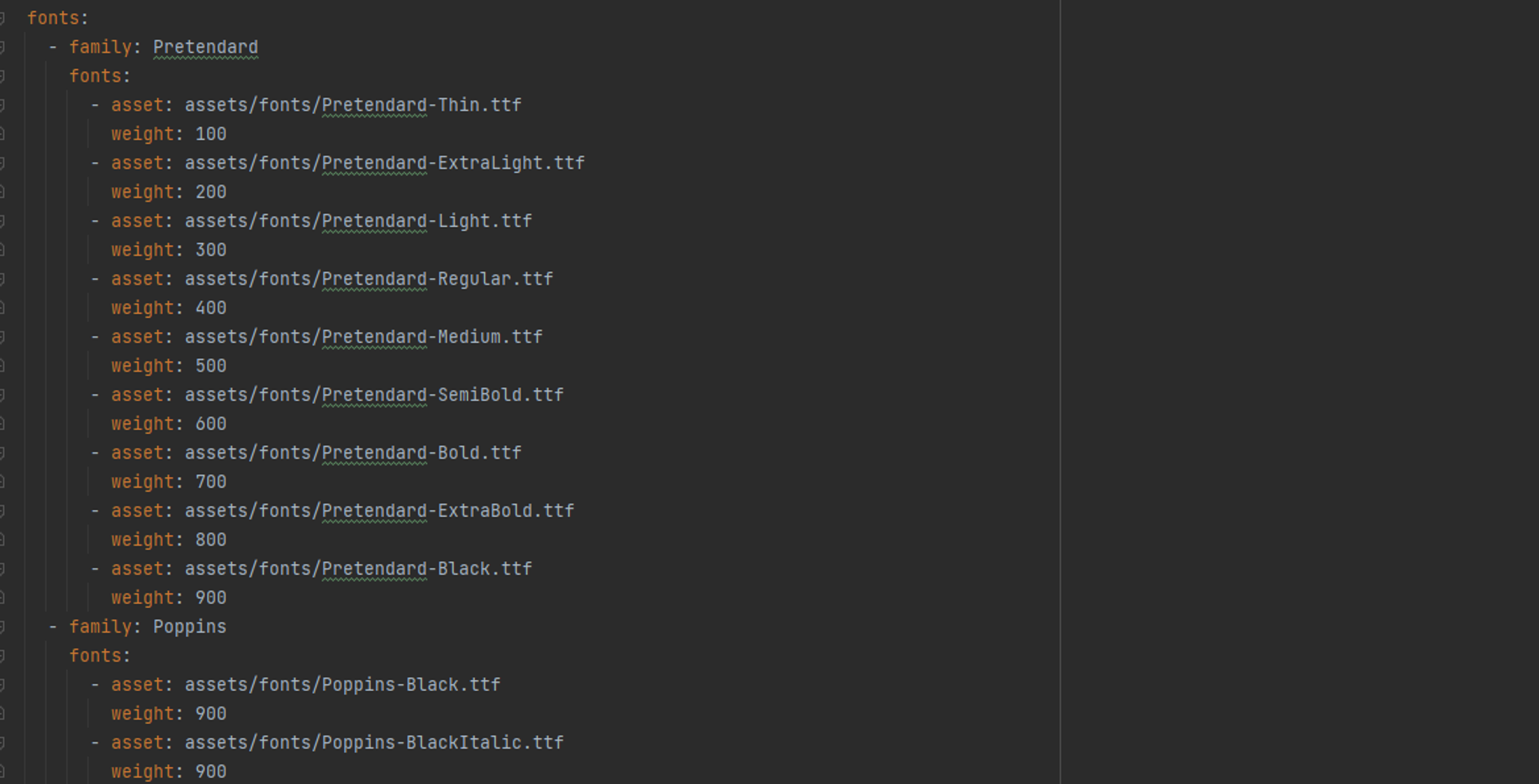
2) 프로젝트 전체 스타일 적용
lib > style.dart 파일에 전체 뷰에 일괄적으로 적용할 수 있는 스타일 코드를 작성하였다.
작성한 style.dart 코드는 import해서 사용 가능하며,
Material App에 작성하여 모든 위젯에 공통 스타일 적용되도록 한다.
import './style.dart' as 별칭;
void main() {
runApp(
MaterialApp(
theme: 별칭명.변수명,
home : MyApp()
)
);
}
작성한 style.dart 파일은 다음과 같다.
(해당 style.dart 코드를 아직 적용하지 않고, 하드 코딩한 상태인데,, 나중에 리팩토링하면서 고쳐야할 것 같다..🥲)

프론트엔드 개발
프로젝트 세팅을 마친 후 본격적으로 프로젝트 개발에 들어갔다.
아래와 같이 팀원과 역할을 분담하여 프로젝트 개발을 진행하였다.
[ 앱 초기화면, 로그인, 회원가입, 보유카드 등록, 마이월렛, 마이페이지 정보 수정, 월별 혜택 조회, CODEF 주카드 등록 페이지] 를 맡아 개발하게 되었다.

뷰 개발과 관련해서는 단순히 피그마에 디지인된 화면대로 코드를 작성하면 돼서 어렵지 않았지만,
서버 API와 연결하는 과정에서 처음에 어려움을 많이 겪었어서,
해당 부분에 대해 자세하게 기술하고자 한다.
프론트 - 서버 API 연결
서버 API 연결을 위해, Dart Dio 패키지를 이용하였다.
아래의 공식문서를 참고하면 쉽게 코드를 작성할 수 있다.
dio | Dart package
A powerful HTTP networking package, supports Interceptors, Aborting and canceling a request, Custom adapters, Transformers, etc.
pub.dev
먼저, pubspec.yml 파일의 dependencies에
dio 패키지를 추가한 후 pub get 해준다.
(dio 4.0.0 버전을 사용하였다.)
예를 들어 월별 혜택 조회를 위한 API 연결 코드를 작성해보자.
API 명세서를 확인해보면 다음과 같다.
HTTP method : GET
URI : /mypage/benefit?month=8
Request Header : { "Authorization" : "[사용자별 Access Token]" }
Query Parameter : month (Int type)
앞선 명세서를 참고하여 dio를 이용한 API 연결 코드는 다음과 같다.
먼저 apiUrl 에 BASE_URL에 해당 URI를 추가하여 작성해주면 된다.
이때 Query Parameter의 값은 $ 뒤에 변수 명을 작성하여준다.
(BASE_URL을 상단에 Constants.baseUrl로 지정하여 유출되지 않도록 하였다.)
final String BASE_URL = Constants.baseUrl;
다음으로 Request Header의 사용자의 AccessToken이 필요한데,
FlutterSecureStorage 패키지를 이용하여 저장한 AccessToken을 불러올 수 있도록 하였다.
https://pub.dev/packages/flutter_secure_storage
flutter_secure_storage | Flutter package
Flutter Secure Storage provides API to store data in secure storage. Keychain is used in iOS, KeyStore based solution is used in Android.
pub.dev
이후 dio를 이용하여 앞서 작성한 apiUrl을 Get 메소드로 불러오도록 한후,
응답값을 Map<dynamic, dynamic> 형태의 responseData 변수에 넣으면,
해당 responseData를 파싱하여 원하는 응답값을 사용할 수 있다.
// [Get] 월별 혜택 조회
Future<void> _getMontlyBenefit(BuildContext context) async {
final String apiUrl = '${BASE_URL}/card/benefit?month=$_month';
const storage = FlutterSecureStorage();
String? storedAccessToken = await storage.read(key: 'accessToken');
final baseOptions = BaseOptions(
headers: {'Authorization': 'Bearer $storedAccessToken'},
);
final dio = Dio(baseOptions);
try {
var response = await dio.get(apiUrl);
Map<dynamic, dynamic> responseData = response.data;
print(responseData);
if (responseData['code'] == 1000) {
_updateBenefitState(responseData);
}
} catch (e) {
// ** 차후 수정 필요 **
print(e.toString());
showDialog(
context: context,
builder: (BuildContext context) {
return AlertDialog(
title: Text("오류 발생"),
content: Text("서버와 통신 중 오류가 발생했습니다."),
actions: [
TextButton(
onPressed: () {
Navigator.pop(context);
},
child: Text("확인"),
),
],
);
},
);
}
}
다른 API 역시 위와 동일한 방식으로 dio 패키지를 이용하여 연결하였고,
추가적인 프론트엔드 코드 아래의 github 페이지에서 확인할 수 있다.
[ Front-End github ]
https://github.com/EWHA-LUX/ONCE-FE
GitHub - EWHA-LUX/ONCE-FE
Contribute to EWHA-LUX/ONCE-FE development by creating an account on GitHub.
github.com
4. Back-End SpringBoot API 개발
백엔드 개발은 SpringBoot 3.1.6 버전을 이용하여 진행하였다.
먼저 ERD를 설계하고, API 명세서를 작성한 후, API 개발을 시작하였다.
ERD 설계
ERD Cloud를 이용하여 작성하였으며, 최종 설계된 ERD는 다음과 같다.
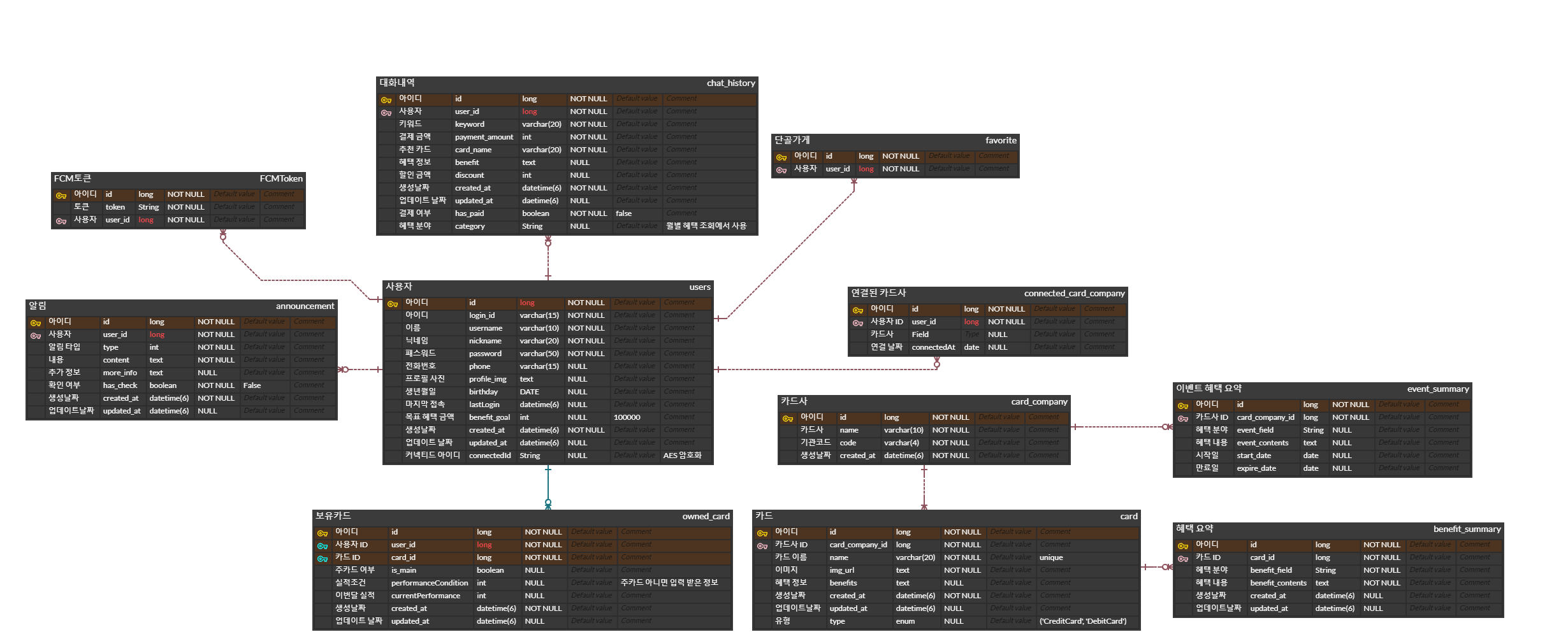
API 명세서 작성
다음으로 설계한 ERD와 UI를 바탕으로 API 명세서를 작성하였다.

API 개발
[ 아이디 중복 확인, 로그아웃, 비밀번호 확인, 비밀번호 변경, 회원 정보 수정, 마이월렛 조회, 주카드 아닌 카드 실적 입력, 월별 혜택 조회, 목표 혜택 금액 입력 ] API를 맡아 개발하게 되었다.
1) 엔티티 생성
앞서 작성한 ERD를 바탕으로, 각 테이블에 해당되는 엔티티를 작성해준다.
User 엔티티의 예시 코드는 다음과 같다.
각 ERD 칼럼에 해당되는 값을 필드로 작성해주고,
해당 칼럼의 특성을 @Column 어노테이션 안에 작성해주면 된다.
package ewha.lux.once.domain.user.entity;
import ewha.lux.once.domain.user.dto.EditUserInfoRequestDto;
import ewha.lux.once.global.common.BaseEntity;
import ewha.lux.once.global.common.ColumnEncryptor;
import jakarta.persistence.*;
import lombok.*;
import org.springframework.security.core.GrantedAuthority;
import org.springframework.security.core.authority.SimpleGrantedAuthority;
import org.springframework.security.core.userdetails.UserDetails;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Date;
import java.sql.Timestamp;
import java.util.List;
@Entity
@Table(name="User")
@Getter
@Builder
@NoArgsConstructor(access= AccessLevel.PROTECTED)
@AllArgsConstructor
public class Users extends BaseEntity implements UserDetails {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "userId")
private Long id;
@Column(name = "loginId", nullable = false, unique = true)
private String loginId;
@Column(name = "username", nullable = false)
private String username;
@Column(name = "nickname", nullable = false)
private String nickname;
@Column(name = "password", nullable = false)
private String password;
@Column(name = "phone")
private String phone;
@Column(name = "profileImg")
private String profileImg;
@Temporal(TemporalType.DATE)
@Column(name = "birthday")
private Date birthday;
@Temporal(TemporalType.TIMESTAMP)
@Column(name = "lastLogin")
private Timestamp lastLogin;
@Column(name = "benefitGoal")
private int benefitGoal;
@Column(name = "connectedId")
@Convert(converter = ColumnEncryptor.class)
private String connectedId;
@Override
public Collection<? extends GrantedAuthority> getAuthorities() {
List<GrantedAuthority> authorities = new ArrayList<>();
authorities.add(new SimpleGrantedAuthority("USER")); // 사용자에게 기본적인 권한을 부여
return authorities;
}
@Override // 계정 만료 여부 반환
public boolean isAccountNonExpired() {
return true;
}
@Override // 계정 잠금여부 반환
public boolean isAccountNonLocked() {
return true;
}
@Override // 패스워 만료 여부 반환
public boolean isCredentialsNonExpired() {
return true;
}
@Override // 게정 사용 가능 여부 반환
public boolean isEnabled() {
return true;
}
@PreUpdate
public void setLastLogin() {
this.lastLogin = new Timestamp(System.currentTimeMillis());
}
public void editUserInfo(EditUserInfoRequestDto requestDto){
if (requestDto.getUsername() != null)
this.username = requestDto.getUsername();
if (requestDto.getNickname() != null)
this.nickname = requestDto.getNickname();
if (requestDto.getBirthday() != null)
this.birthday = requestDto.getBirthday();
if (requestDto.getUserPhoneNum() != null)
this.phone = requestDto.getUserPhoneNum();
}
public void setProfileImg(String profileImg) {
this.profileImg = profileImg;
}
public void updatePassword(String password) {
this.password = password;
}
public void setCardGoal(int goal) {this.benefitGoal = goal;}
public void setConnectedId(String connectedId) {this.connectedId = connectedId;}
}
2) 응답 코드 생성
코드 개발을 용이하게 하기 위해 응답 코드를 지정하여,
Response를 생성하도록 코드를 작성하였다.
1000번대는 Requst 성공 메시지, 2000번대는 Request 오류 메시지, 3000번대는 Response 오류 관련 메시지를 표시하도록 작성하였다.
3) API 개발
API의 경우 Service, Controller, Dto 관점에서 나누어 생각하면 보다 쉽게 개발가능하다.
비밀번호 확인 API를 확인해보자.
[ Dto ]
먼저 Dto의 경우, 비밀번호 확인을 위해서는 비밀번호 필드만 Request Body로 입력받으면 되므로,
password 필드가 있는 Dto를 작성해준다.
package ewha.lux.once.domain.user.dto;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
public class ChangePasswordDto {
private String password;
}
[ Controller ]
- @PostMapping : Post 메소드를 사용하므로 해당 어노테이션을 사용한다.
- value 안에 해당 API URI를 작성해준다.
- Request Header에 Access Token이 필요하므로, @AuthenticationlPrincipal을 이용하여 유저 정보를 가져오도록 한다.
- RequestBody로는 앞서 만든 Dto 클래스를 작성해준다.
- 이후 해당 API를 위한 상세 서비스 로직은 Controller가 아닌 Service에서 작성해야 하므로, userService의 postCheckPassword 메소드의 return 값을 Response로 응답하도록 작성한다.
// [Post] 비밀번호 확인
@PostMapping(value = "/edit/pw")
@ResponseBody
public CommonResponse<?> checkPassword(@AuthenticationPrincipal UserAccount userAccount, @RequestBody ChangePasswordDto checkPasswordRequestDto) {
try {
return new CommonResponse<>(ResponseCode.SUCCESS, userService.postCheckPassword(userAccount.getUsers(), checkPasswordRequestDto));
} catch (CustomException e){
return new CommonResponse<>(e.getStatus());
}
}
[ Service ]
앞서 작성한 Controller의 세부 서비스 로직을 수행하기 위한 코드를 작성한다.
passwordEncoder를 사용하여 Dto Request Body로 입력받은 password와 현재 user의 password가 동일하다면
true 값을 return하도록 설계한다.
public boolean postCheckPassword(Users nowUser, ChangePasswordDto checkPasswordRequestDto) throws CustomException {
return passwordEncoder.matches(checkPasswordRequestDto.getPassword(), nowUser.getPassword());
}
다른 API 역시 위와 동일한 방식으로 개발을 완료하였으며,
추가적인 백엔드 코드는 아래의 github 페이지에서 확인할 수 있다.
[ Back-End github ]
https://github.com/EWHA-LUX/ONCE-BE
GitHub - EWHA-LUX/ONCE-BE
Contribute to EWHA-LUX/ONCE-BE development by creating an account on GitHub.
github.com