4.0 4주차 워크북 학습 목표
4주차는 백엔드 서버의 핵심인 데이터베이스 설계 방법을 알아보고,
요구 사항에 따라 어떻게 설계하는 것이 좋은 설계 방법인지 학습해보자.
데이터베이스를 잘 설계하는 방법 알아보기!
1) 유저 테이블 설계 방법 학습하기
2) N:M (다대다) 관계 설정 방법 학습하기
3) 알림을 보내야 하는 경우 설계 방법 학습하기
아래는 4주차 워크북을 수행하기 위해 알아야 하는 사전 개념을 간단하게 정리해보았다.
데이터베이스 수업에서 다루었던 내용이지만,
까먹은 부분이 많아 간단하게 다시 복습해보았다.
해당 내용에 대해서는 차후 블로그에 다시 자세하게 정리해 보아야 겠다!
[ 사전 개념 (1) - 관계형 데이터 베이스 ]
- 데이터를 table(표) 의 형태로 표시하는 방법
- 이 table의 묶음이 하나의 데이터베이스가 됨
- RDBMS(Relational Database Management System)은 관계형 데이터베이스를 관리하는 시스템
- SQL(Structured Query Language)는 관계형 데이터베이스를 다루기 위한 표준 언어
- MySQL은 대표적인 RDBMS
[ 사전 개념 (2) - MySQL 기본 문법 ]
1) 데이터베이스와 테이블 생성
- CREATE DATABASE [데이터베이스 명] : 데이터베이스 생성
- DROP DATABASE [데이터베이스 명] : 데이터베이스 제거
- SHOW DATABASE : 데이터베이스 목록
- USE [데이터베이스 명] : 데이터베이스 선택
- CREATE TABLE [테이블 명] : 테이블 생성
[ 예시 ]
USE mydb; CREATE TABLE topic( id INT(11) NOT NULL AUTO_INCREMENT, title VARCHAR(100) NOT NULL, description TEXT NULL, created DATETIME NOT NULL, author VARCHAR(30) NULL, profile VARCHAR(100) NULL, PRIMARY KEY(id) )
- INT(정수), TEXT(긴 문자열), VARCHAR(변경가능한 문자열)
- NOT NULL : 해당 칼럼이 비어있으면 안되도록 설정
- AUTO_INCREMENT : 칼럼 값이 1씩 증가하도록 설정
- INT(11) 소괄호 : 명령창에 노출시킬 데이터(행)의 개수
- VARCHAR(100) 소괄호 : 최대 글자 수
- PRIMARY : 해당 칼럼의 값을 기본키로 하여 유일한 값이 되도록 하는 예약
2) 데이터의 CRUD
- INSERT INTO [ 데이터를 삽입할 어트리뷰트명 ] VALUES [ 삽입할 데이터 값 ] : 데이터 생성
- SELECT [ 선택할 어트리뷰트명] FROM [ 데이터베이스명 ] WHERE [ 조건 ] : 데이터 선택
- UPDATE [ 데이터베이스명 ] SET [ 수정된 데이터 값 ] WHERE [ 조건 ] : 데이터 수정
- DELETE FROM [ 데이터베이스 명 ] WHERE [조건] : 데이터 삭제
[ 사전 개념 (3) - ERD 설계 ]
- ERD(Entity Relationship Diagram)은 데이터베이스 구조를 한눈에 보기 위한 데이터 모델링 방법
- Entity, Relationship, Attribute를 중점으로 그린 다이어그램
- 요구분석사항에서 얻은 엔티티와 속성의 관계를 그림으로 표현
4.1 Database 요구사항
데이터 베이스는 언제 설계하는 것이 좋을까?
데이터베이스의 설계 결과물인 ERD는 프로젝트 시작과 동시에 설계하는 것이 좋다!
ERD의 세세한 내용은 실제 구현 과정에서 계속해서 변경될 수 있지만,
팀원이 공통된 데이터베이스를 인지하기 위해 1차적으로 큰 틀을 작성해야 한다.
그렇다면 데이터베이스 요구사항을 바탕으로
실제 데이터베이스를 설계하는 실습을 하나씩 진행해보자.
먼저 도서 대여 관리 App을 위한 요구사항은 다음과 같다.
[ 사용자 관련 요구사항 ]
1) 카카오 소셜 로그인 구현 예정
2) 회원 탈퇴 기능 필요
3) 이름, 닉네임, 전화번호, 성별 필요
[ 책 관련 요구사항 ]
1) 사용자는 여러 권의 책을 대여 가능
2) 책은 하나의 카테고리가 있음
3) 책은 제목, 설명에 대한 정보가 필요
4) 책 소개 페이지에 해시태그가 붙을 수 있고, 책 한 권에 해시태그 여러 개가, 해시태그 하나가 여러권의 책에 붙을 수 있음
5) 사용자가 책 설명 페이지에서 책에 좋아요를 누를 수 있음
6) 책 카테고리 별로 현재 몇 개의 책이 있는지 집계
[ 알림 관련 요구사항 ]
1) 공지 관련 알림
2) 책 반납 시간 임박 알림
3) 마케팅 알림
4.2 Database 엔티티 칼럼 설계하기
위의 요구사항을 바탕을 데이터베이스를 설계해보자.
먼저 설계를 바탕으로 작성한 ERD 는 아래와 같다.

위의 다이어그램에서 먼저 엔티티를 바탕으로
데이터베이스 설계방법을 자세하게 알아보자.

기본적인 설계 방법
먼저 모든 엔티티에 기본적으로 적용되는 설계 방법은 다음과 같다.
1. 테이블 이름과 칼럼 이름은 소문자로 작성
2. 단어 구분은 대소문자가 아닌 밑줄로 구분
3. 각 엔티티 정보 중 유일한 값을 기본 키로 설정하기 보다는 id로 두는 것이 좋음
( book_id, member_id 등으로 나타내기 보다는 그냥 id 로 나타낼 것)
4. 기본 키 타입은 int가 아닌 추후 서비스 확장을 위해 bigint로 하기
5. created at, updated at 을 테이블 마다 추가하는 것이 좋음
실제로 테이블과 칼럼 이름은 book, id 로 소문자로 표시하였다.
또한 기본 키 값을 id 로 별도로 두고, 타입은 bigint로 설정한 것을 확인할 수 있다.
또한 created at, updated at 여시 작성하였다.
member 테이블 설계 방법
멤버 테이블의 경우 기존 테이블에서 추가적인 기능이 필요하다.
회원 탈퇴, 게시글 삭제의 경우 HTTP Method 중 Delete 로 바로 삭제할 수 있다.
하지만 이러한 Hard Delete 방식은 사용하지 않는 것이 좋다!
예를 들어 매일 인기 있는 사용자 상위 5명을 집계해서 보여준다고 할 때,
상위 1등이 갑자기 탈퇴를 하고 Hard Delete를 하는 경우
1등 없이 2, 3, 4, 5 등만 존재하게 된다.
또한 사용자가 회원 탈퇴를 철회하고 싶은 경우
정보를 다시 불러올 수 있는 방법이 없다.
따라서 회원 탈퇴나 게시물 삭제의 경우,
일단 이를 비활성 상태로 둔 후, 일정 기간 동안 비활성인 경우 자동 삭제하는 것이 좋다!
이러한 방식은 Soft Delete라고 하는데,
batch (정해진 시간에 자동으로 실행되는 프로세스)를 이용하여
매일 특정한 시간 member 테이블을 검사하고, 일정시간 inactive된 member를 삭제하도록 한다.
이러한 Soft Delete는 HTTP Method는 Patch에 해당된다.
Soft Delete를 수행하기 위해
아래의 2가지 칼럼을 member 엔티티에 추가해보자.
1) status / varchar (15)
2) inactive_delete / datetime
status의 경우 active(활성화) / inactive(비활성화) 를
enum으로 관리하기 위해 varchar(15)로 둔다.
이는 boolean 타입으로 두어 0이면 비활성, 1이면 활성 상태로 설정해도 된다.

alarm 테이블 설계 방법
알림의 경우 아래와 같은 요구사항을 포함하는 경우 까다로워 진다.
1) 공지 사항에 대한 알림은 알림 터치 시 공지사항으로 이동
2) 마케팅 알림의 경우 알림 터치 시 해당 마케팅으로 이동
위와 같은 요구사항의 경우
해당 알림이 어떤 것에 대한 알림인지 어떻게 구분해야 할까?
이를 설계하기 위한 3가지 방법을 알아보자.
1) 슈퍼 타입과 서브 타입으로 구성
alarm 엔티티 아래에 notice와 marketing 서브 엔티티를 설계한다.

2) 하나의 테이블에 두고 dtype으로 구분
dtype을 테이블로 따로 관리하거나 enum으로 괸리하여
간단하게 모든 내용을 한 테이블에 두기

3) 모든 테이블을 다 나누기
단순하게 notice_alarm, marketing_alarm 으로 나누어 구현할 수 있다.

4.3 Database 엔티티 타입 설계하기
앞서 작성한 칼럼의 타입은 어떻게 설정하는 것이 좋은지 알아보자.
기본적인 타입 설정 방법
각 칼럼의 타입은 PM 에게 물어보는 것이 가장 정확하므로,
와이어 프레임이 있다고 하더라도 헷갈리는 부분은
PM에게 적극적으로 물어보는 것이 좋다!
먼저 위의 다이어그램에서 사용된 타입을 하나씩 살펴봐서
기본적인 타입 사용법을 익혀보자.
varchar(40)
위에서 name의 타입은 varchar(40) 으로 작성되어 있다.
이는 MySQL에서 유니코드 기준으로 40글자를 뜻하므로,
한글 40글자까지 나타내겠다는 의미이다.
text
다음으로 description의 타입은 text 타입으로 작성되어 있다.
text 타입은 마치 String 처럼 제한이 없는 문자열을 나타낸다.
하지만 실제로는 PM과 상의하여 글자 수 제한을 정하는 것이 좋다!
datetime(6)
created at 과 updated at 의 경우 datetime(6) 로 작성되어 있는 것을 확인할 수 있다.
여기서 (6) 은 소수점 6자리까지 구분한다는 뜻이다.
그렇다면 왜 밀리초까지 구분하는 것일까?
이는 최신 순 정렬을 염두해 둔 설계이다.
예를 들어 동시에 책을 등록하여 created_at이 초 단위까지 같은 경우,
최신 순 정렬이 힘들어지므로 밀리 초 소수점까지 구분을 하도록 한다.
MySQL에서는 최대 6자리까지 구분가능하다.
성별 타입 설정 방법
아래의 member 엔티티에서 gender라는 성별을 나타내는 칼럼을 추가하였다.

성별의 경우 아래의 두 가지 타입으로 나타낼 수 있다.
1) 0이면 남자, 1이면 여자
2) varchar로 설정하여 문자로 두고, enum으로 관리
4.4 Database 엔티티 간 관계 설정하기
RDB를 기반으로 하는 MySQL은 외래키로 연관 관계를 표시하게 된다.
각 엔티티간 연관관계를 하나씩 자세하게 살펴보자.
book 과 member 간 연간관계
사용자가 책을 대여하는 연관 관계는 어떻게 표현할 수 있을까?
book 엔티티는 실제 책 한 권을 말하는 것이 아니라,
책 종류를 의미하게 된다.
한 종류의 책을 여러 사용자가 대여하고, 한 사용자가 여러 권의 책을 대여하므로
사용자와 책은 N : M 관계가 성립한다.
N : M 관계는 양쪽의 기본 키를 외래 키로 가지고 각각 1 : N 관계를 가지는
매핑 테이블을 따로 두어야 한다!
아래의 다이어그램을 보면
book 과 member 엔티티 사이에 rent 매핑 테이블을 생성하였다.

book 과 book_category 간 연간관계
책과 책 카테고리간의 연관 관계는 어떻게 표현할 수 있을까?
앞선 요구사항에서 책은 한 종류의 카테고리만 갖게 된다.
이때 한 카테고리에는 여러 종류의 책이 속하게 되므로,
카테고리와 책은 1 : N 관계가 성립된다.

book 과 book_hashtag, book_likes 간 연간관계
하나의 책에는 여러개의 해시태그와 좋아요를 달 수 있고,
각 해시태그와 좋아요는 여러 책에 달릴 수 있으므로
두 관계 모두 N : M 관계에 해당된다.
따라서 이를 위한 매핑 테이블을 추가하면
아래와 같은 다이어그램을 완성할 수 있다.

[ book_likes 설계 방법 참고 ]
좋아요 기능의 경우 책 테이블에 like 칼럼을 두고 +1 / -1 연산을 수행할 수도 있다.
하지만 사용자 간 차단 기능이 생기는 경우
이는 집계하지 않는다는 요구사항이 추가되는 경우를 대비하여
순수 DML 연산으로 book_likes 엔티티에서 해당 책 아이디를 가진 것이 몇 개인지 직접 세는 것이 좋다!
4.5 RDS의 설정
데이터 베이스는 어디에 두는 것이 좋을까?
데이터베이스가 로컬에 있는 경우 컴퓨터를 끄면 접속이 불가능하고,
다른 컴퓨터에서 접속하기 위해서는 포트포워딩을 해야하므로 적절하지 않다.
따라서 데이터베이스도 EC2 처럼 외부 컴퓨터를 빌려야 하는데,
RDS를 사용하면 쉽고 유연하게 데이터베이스를 사용할 수 있다.
RDS를 설정하는 방법을 차례대로 알아보자.
1) 서브넷 추가 생성
앞서 만들었던 퍼블릭 서브넷 UMC-5th-practice VPC에 RDS를 배치해보자.
RDS를 VPC 서브넷에 배치하기 위해서는 만약을 위해 2개의 서브넷을 지정해야 한다.
( 서브넷 생성 자세한 방법 정리 자료 참고 )
https://wlalsu.tistory.com/113
[UMC Server] Chapter 2. AWS(VPC & Internet Gateway & EC2)
2.0 2주차 워크북 학습 목표 서버의 인프라 구축을 위해 AWS에 대한 학습을 진행해보자. 1) AWS의 VPC를 이해한다. 2) 서버가 어떻게 구축되는지 이해한다. 2주차는 AWS VPC에 대한 이론을 다룬 후, EC2 구
wlalsu.tistory.com
새로운 서브넷 생성 창에서
아래와 같이 VPC를 설정하고, 10.0.3.0/24 서브넷을 생성한다.
이때 2개의 서브넷이 다른 가용영역을 사용하도록 설정한다.
[ 참고 ]
10.0.1.0/24 (서브넷을 이어서 만들 때는 10.0.2.0/24, 10.0.3.0/24 … 설정)

다음으로 생성한 서브넷을 퍼블릭 서브넷으로 만들기 위해
외부와 연결이 된 라우팅 테이블에 연결해준다.
라우팅 메뉴에서 해당 VPC를 선택한 후,
서브넷 연결 > 서브넷 연결 편집을 클릭한다.

앞서 생성한 2개의 서브넷을 클릭한 후
연결 저장 버튼을 클릭하면 완료된다.

2) RDS 설정
다음으로 새롭게 만들 DB 를 퍼브릭 서브넷에 배치하기 위해
DB 서브넷을 생성해보자.
RDS 메뉴에 들어간 후
서브넷 그룹 > DB 서브넷 그룹을 생성 버튼을 클릭한다.
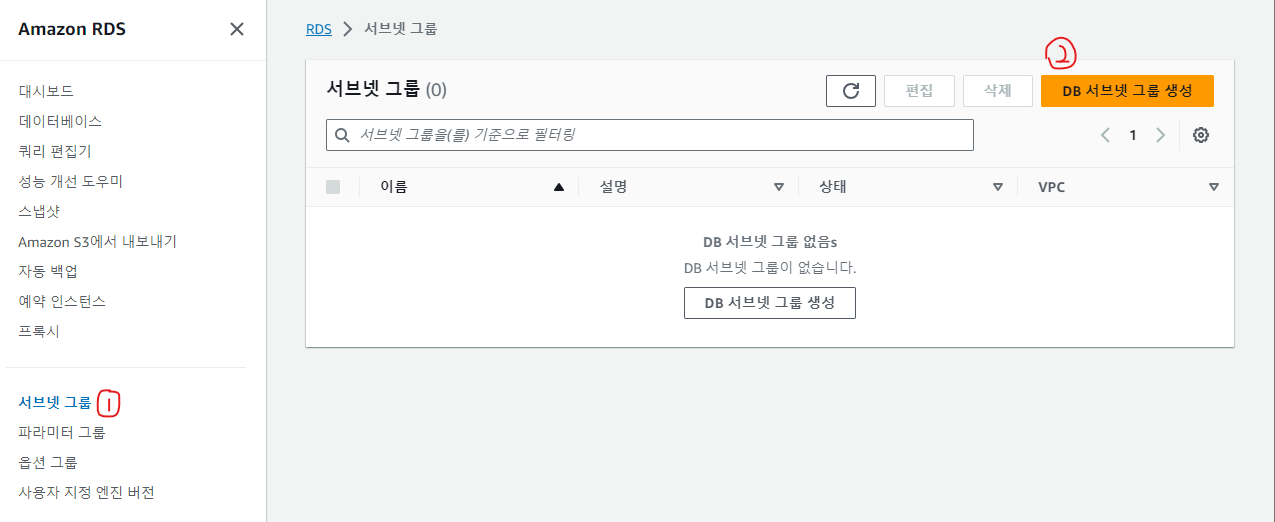
이름과 설명을 작성하고,
원하는 VPC를 선택한 후, 퍼블릭 서브넷 2개를 선택한다.
이때 두개의 서브넷이 서로 다른 가용영역을 갖는다.
(실패 오류 메시지가 뜬다면 앞선 단계에서 서브넷이 다른 가용영역을 갖도록 다시 생성)

다음으로 DB를 생성하기 위해
좌측의 데이터베이스 > 데이터 베이스 생성 버튼을 클릭한다.

먼저 표준 생성과 원하는 엔진 유형 (MySQL)을 선택한다.

템플릿은 프리 티어로 설정한다.

DB 인스턴스 식별자 이름을 작성하고,
마스터 사용자 이름은 편한 것으로 설정한다. (주로 root 사용)
마스터 암호는 잊어버리지 않도록 유의하자!

요금 부과를 막기 위해
스토리지 자동 조정 활성화 버튼은 켜둔다.

연결하고 싶은 VPC와 앞서 생성한 DB 서브넷 그룹을 선택한 후,
퍼블릭 액세스를 yes로 설정한다.
보안그룹은 앞서 2장에서 만들어 두었던 보안그룹을 사용한다.


마지막으로 자동 백업을 비활성화 하고
데이터베이스 생성 버튼을 클릭하면 아래와 같이 실패 메시지가 뜬다.

실패 메시지를 확인해보면 DNS 관련 설정이 없어서임을 확인할 수 있다.
VPC에서 DNS 설정을 활성화 해주고 다시 RDS를 만들어보자.

아래처럼 DNS 호스트 이름 활성화해준다.

이후 다시 앞서 만들었던 것과 동일하게 RDS 를 만들어준다.
만약 빨간 줄이 뜬다면 아래의 인증서 업데이트를 수행해주면 된다.

3) RDS 원격접속



최용욱 'UMC Server 4주차 워크북' 내용을 기반으로 작성하였습니다.
'[UMC Ewha 5th] Server - SpringBoot' 카테고리의 다른 글
| [UMC Server] Chapter 6. API URL의 설계 & 프로젝트 세팅 (0) | 2023.11.15 |
|---|---|
| [UMC Server] Chapter 5. 실전 SQL - 어떤 Query를 작성해야 할까? (0) | 2023.11.07 |
| [UMC Server] Chapter 3. Web Server & Web application Server(WAS), Reverse Proxy (1) | 2023.10.09 |
| [UMC Server] Chapter 2. AWS(VPC & Internet Gateway & EC2) (0) | 2023.10.04 |
| [UMC Server] Chapter 1. 서버란 무엇인가(소켓&멀티 프로세스) (1) (0) | 2023.09.27 |