5.0 5주차 워크북 학습 목표
5주차는 각각의 요구사항에 따라
어떻게 SQL 쿼리를 짜는 것이 좋은지 학습해보았다.
1) 4주차 예시를 기반으로 요구사항에 대한 SQL 쿼리 짜기
2) paging을 고려하여 쿼리 작성하기
MySQL을 기준으로 쿼리를 작성하였고,
4주차에서 실습한 ERD를 바탕으로 SQL 쿼리를 짜는 실습을 진행하였다.
아래는 5주차 워크북을 수행하기 위해 알아야 하는 사전 개념을 간단하게 정리해보았다.
[ 참고 ] 테이블 join의 개념
- 서로 다른 각각의 테이블안에 있는 데이터를 동시에 보여주어야 할 때 사용
- 조인을 위해서 두 테이블은 기본키, 외래키 관계 (일대다 관계) 로 맺어져 있어야 함
1) Inner Join : 두 테이블에 해당 데이터가 모두 존재하는 경우 가능으로 일반적인 방법
2) Outer Join : 교집합 위부에 존재하는 데이터를 가져오며, Left Join, Right Join, Full Join이 있다.
3) Cross Join : 한 테이블의 모든 행과 다른 테이블의 모든 행을 조인 (카티션 곱)
4) Self Join : 자기 자신과 조인
[참고자료]
https://inpa.tistory.com/entry/MYSQL-%F0%9F%93%9A-JOIN-%EC%A1%B0%EC%9D%B8-%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C-%EC%95%8C%EA%B8%B0%EC%89%BD%EA%B2%8C-%EC%A0%95%EB%A6%AC
[MYSQL] 📚 테이블 조인(JOIN) - 그림으로 알기 쉽게 정리
SQL JOIN JOIN은 데이터베이스 내의 여러 테이블에서 가져온 레코드를 조합하여 하나의 테이블이나 결과 집합으로 표현해 주는, Relation Database 에서 가장 많이 쓰이는 녀석이다. (INNER) JOIN 조인하는
inpa.tistory.com
[ 참고 ] 서브쿼리(SubQuery)의 개념
- 하나의 SQL문 안에 포함되어 있는 또 다른 SQL문
- 메인쿼리가 서브쿼리를 포함하는 종속관계 (메인쿼리는 서브쿼리 칼럼을 사용할 수 없음)
- 서브쿼리 레벨과는 상관없이 항상 메인쿼리 레벨로 결과 집합이 생성
- 서브쿼리는 괄호( ) 안에 존재
- SELECT문으로만 작성할 수 있음
- 괄호가 끝나고 끝에 세미콜론 ( ; ) 을 사용하지 않음
- ORDER BY 사용할 수 없음
// 메인 쿼리 select * from main_table where target_id in ( // 서브 쿼리 select id from sub_table where id < 500 );
[ 참고자료 ]
https://inpa.tistory.com/entry/MYSQL-%F0%9F%93%9A-%EC%84%9C%EB%B8%8C%EC%BF%BC%EB%A6%AC-%EC%A0%95%EB%A6%AC
[MYSQL] 📚 서브쿼리 개념 & 문법 💯 정리
서브쿼리(Subquery) 서브쿼리(subquery)란 다른 쿼리 내부에 포함되어 있는 SELETE 문을 의미한다. 서브쿼리를 포함하고 있는 쿼리를 외부쿼리(outer query)라고 부르며, 서브쿼리는 내부쿼리(inner query)라
inpa.tistory.com
5.1 Query 작성해보기
앞서 4주차 본문과에서 실습한 ERD를 바탕으로
쿼리를 짜는 실습을 진행하였다.
[ 4주차 ERD 참고 ]
https://wlalsu.tistory.com/117
[UMC Server] Chapter 4. Database 설계 & AWS RDS 설정
4.0 4주차 워크북 학습 목표 4주차는 백엔드 서버의 핵심인 데이터베이스 설계 방법을 알아보고, 요구 사항에 따라 어떻게 설계하는 것이 좋은 설계 방법인지 학습해보자. 데이터베이스를 잘 설
wlalsu.tistory.com
쿼리를 짜는 것에는 정해진 답이 없기 때문에
join 또는 subquery에 대한 선택은 상황에 따라 자율적으로 정하면 된다.
단 너무 무리한 query를 한번에 보내기보다는
적당한 크기의 query로 쪼개서 보내는 것이 좋다.
앞서 작성한 ERD를 바탕으로
데이터베이스 query를 작성해보자.
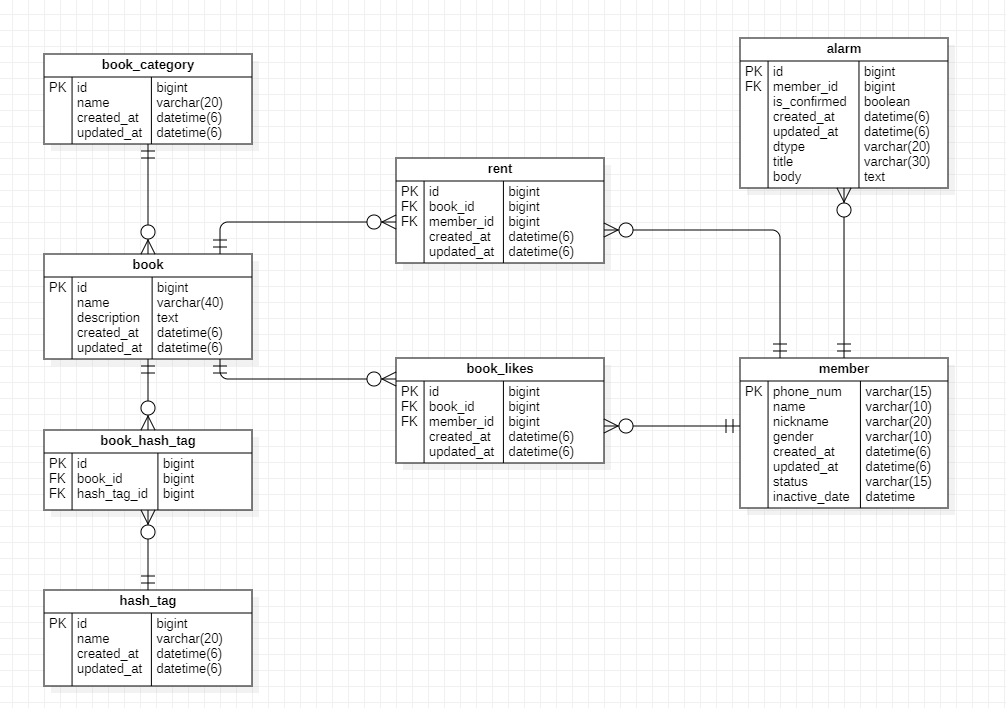
2) 책이 받은 좋아요 개수 보여주기
단순하게 책 테이블에 좋아요 개수를 확인할 수 있는 칼럼을 작성했다면,
book 테이블에서 likes 정보를 추출할 수 있다.
select likes from book;
하지만 위의 ERD에서 설계했듯이,
book_likes 테이블이 따로 존재한다면,
아래와 같이 대상 책 id를 바탕으로 book_likes 테이블에서 카운트 해야 한다.
select count(*)
from book_likes
where book_id = {대상 책 id}
이때 차단 테이블을 따로 생성하여,
내가 차단한 사용자의 좋아요의 개수는 집계하지 않는다고 가정해보자.
이때는 block 테이블에서 내가 차단한 사용자의 아이디를 찾은 후,
해당 아이디는 집계하지 않는 쿼리를 추가해주어야 한다.
아래의 쿼리는 subquery를 이용한 방식이다.
// subquery 사용하기
// 내 아이디 = 2, 책 아이디 = 3
select count(*)
from book_likes
where book_id = 3
and user_id not in
(select target_id
from block
where owner_id=2);
만약 위와 동일한 query를 inner join 을 사용하여 나타내는 경우는 아래와 같다.
아이디가 2인 사용자가 차단한 사용자를 추출하기 위해
book_likes의 user_id와 block의 taret_id를 조인한다.
// inner join 사용하기
// 내 아이디 = 2, 책 아이디 = 3
select count(*)
from book_likes as bl
inner join block as b on bl.user_id = b.target_id and b.owner_id=2
where bl.book_id = 3;
동일하게 left join을 사용하는 경우의 쿼리는 아래와 같다.
앞선 inner join의 경우 조인 조건을 만족하는 행만 반환한다.
하지만 left join의 경우 왼쪽 테이블의 모든 행을 포함하기 때문에,
해당 행이 존재하지 않는 경우 null 값으로 채우게 된다.
따라서 target_id가 null인 경우를 쿼리에 추가하여
차단하지 않은 사용자도 식별할 수 있도록 한다.
// left join 사용하기
// 내 아이디 = 2, 책 아이디 = 3
select count(*)
from book_likes as bl
left joinblock as b on bl.user_id = b.target_id and b.owner_id = 2
where bl.book_id = 3 and b.target_id is null;
[ 참고 ] 차단 요구사항을 고려해야 하는 이유
- 커뮤니티 어플리케이션의 경우 런칭을 위해서는 신고/차단 기능을 포함해야 함
- reject를 고려하지 않고 쿼리를 작성하는 경우, 이후에 모든 쿼리를 수정해야 할 수 있음
- 따라서 처음 쿼리를 짤때 차단에 대한 요구사항을 포함하는 것을 잊지말자!
2) 해시태그를 통한 책 검색
앞서 두 개의 테이블이 N : M 관계를 갖는 경우
가운데에 매핑 테이블을 추가해야 함을 배웠다.
이렇게 매핑 테이블이 추가된 경우도
subquery 또는 join 연산을 수행하여 데이터를 가져올 수 있다.
UMC라는 해시태그를 갖고 있는 책을 조회하는 쿼리를 짜보자.
먼저 subquery를 사용하는 경우의 쿼리는 아래와 같다.
먼저 hash_tag 테이블에서 UMC 라는 이름을 가진 hash tag 아이디를 찾고,
해당 아이디와 동일한 id를 가진 book_id를 book_hash_tag 매핑테이블에서 찾은 후,
해당 책을 book 테이블에서 조회하면 된다
select *
from book
where id in
(select book_id
from book_hash_tag
where hash_tag_id = (select id from hash_tag where name = 'UMC')
join 연산을 사용하는 경우의 쿼리는 아래와 같다.
연산을 수행하는 과정은 앞선 subquery를 사용하는 예제와 동일하다.
select b.*
from book as b
inner join book_hash_tag as bht on b.id = bht.book_id
inner join hash_tag as ht on bht.hash_tag_id = ht.id
where ht.name = 'UMC';
3) 최신 순으로 책 목록 조회
앞서 ERD에서 created_at을 통해
ms단위로 책 등록 시간을 저장해놓았으므로,
단순히 created_at을 내림차순으로 조회하여 데이터를 가져올 수 있다.
select *
from book
order by created_at desc;
4) 좋아요 개수 순으로 책 목록 조회
book 테이블에는 likes 칼럼이 없기 때문에
book_likes 테이블과의 join 연산이 필요하다.
먼저 book_likes 테이블에서 book_id 끼리 group을 묶고
book_id에 해당하는 book_like의 개수를 카운트한 후,
해당 좋아요 개수에 따른 내림차순으로 책 데이터를 추출한다.
select *
from book as b
join (select count(*) as like_count
from book_likes
group by book_id) as likes on b.id = likes.book_id
order by likes.like_count desc;
5.2 페이징 (Paging)
앞선 목록 조회 쿼리의 경우
해당 조건을 만족하는 모든 책 데이터를 가져오도록 하였다.
하지만 만약 책 데이터가 100만권이 있다면,
이러한 방식은 오류와 지연을 발생시킬 것이다.
따라서 Paging 을 통해 Database 자체에서 데이터를 끊어서 가져와야 한다!
Paging의 두 가지 방법에 대해 하나씩 자세하게 알아보자.
1) Offset based 페이징
- 페이지 번호로 페이징하는 방법
- 가장 많이 사용되는 페이징 기법
- limit : 한 페이지에서 보여줄 데이터 개수를 정함
- offset : 건너뛸 개수를 지정
아래의 예시는 0개의 데이터를 건너뛴 후,
10개씩 한 페이지에서 데이터를 보여주는 페이징 쿼리이다.
select *
from book
order by likes desc
limit 10 offset 0;
x번째 페이지에서 y개의 데이터를 보여주고 싶다면
아래와 같이 표현할 수 있다.
(x-1번째 페이지까지 y번 데이터를 건너뛴 후, y개의 데이터를 보여주어야 하므로)
select *
from book
order by likes desc
limit y offset(x-1)*y
앞서 작성했던 등록일에 따른 목록 조회 쿼리에 페이징 기법을 사용한다면
아래와 같이 표현할 수 있다.
한 페이지당 15개의 데이터를 표현하도록 하였으며,
(n-1)*15 에 대한 값은 차후 계산해서 집어넣어야 한다.
select *
from book
order by created_at desc
limit 15 offset (n-1)*15;
동일하게 좋아요 수에 따른 목록 조회에 페이징 기법을 사용한다면
아래와 같이 표현할 수 있다.
select *
from book as b
join (select count(*) as like_count
from book_likes
group by book_id) as likes on b.id = likes.boo_id
order by likes.like_count desc
limit 15 offset (n-1) * 15;
[ 추가 ] Offset based 페이징의 단점
- 뒷 페이지의 경우 데이터가 많아져 성능이 떨어짐
- 사용자가 페이지를 넘기는 순간 게시글이 추가되는 경우, 페이지를 넘겨도 동일한 데이터가 보여질 수 있음
2) Cursor based 페이징
- 커서(마지막으로 조회한 콘텐츠)를 가르켜 페이징하는 기법
- 마지막으로 조회한 다음 대상부터 가져옴
아래는 조회한 책의 좋아요 수를 바탕으로
마지막으로 조회한 책의 id를 가져온 후,
Cursor 페이징으로 그 다음 책 데이터를 표시하는 예시이다.
select *
from book
where book.likes < (
select likes
from book
where id = 4)
order by likes desc
limit 15;
책 등록 시간에 따른 책 목록 조회를 위한 커서 페이징 쿼리는 다음과 같다.
책 등록 시간인 created_at을 기반으로
마지막으로 조회한 책의 다음 책을 가져오도록 한다.
select *
from book
where created_at <
(select created_at
from book
where id=3)
order by created at desc
limit 15;
이렇듯 created_at을 기준으로 한 커서 페이징 쿼리는
밀리초 6자리까지 기준으로 하므로 같은 값이 있는 경우가 거의 없다.
하지만 좋아요 수를 기준으로 책을 정렬하는 커서 페이징 쿼리는
좋아요 수가 동일한 경우가 있으므로, 커서 페이징 쿼리가 제대로 동작하지 않을 수 있다.
따라서 좋아요 수만으로 책 목록을 조회하지 않고,
아래의 예시와 같이 좋아요 수가 같은 경우는 최신 순으로 정렬되도록 쿼리를 추가해야 한다.
select *
from book as b
join (select count(*) as like_count
from book_likes
group by book_id) as likes on b.id = likes.book_id
where likes.like_count < (select count(*)
from book_likes
where book_id=3)
order by likes.like_count desc, b.created_at desc
limit 15;
마지막으로 커서 페이징을 이용하여
좋아요 수를 기준으로 책 목록을 조회하되,
차단한 유저의 좋아요는 집계하지 않는 쿼리는 다음과 같다.
앞선 예제와 동일하게 쿼리를 작성하되,
Join의 WHERE절에 block에 해당되는 id는 포함하지 않는 쿼리를 추가한다.
select b.*
from book as b
join (
select bl.book_id, count(*) as like_count
from book_likes as bl
where not exists (
select target_id
from bloxk as bc
where bc.target_id = bl.user_id and bc_owner_id=3
)
group by bl.book_id
) as likes on b.id = likes.book_id
order by likes.like_count desc, b.created_at desc
limit 15;
최용욱 'UMC Server 4주차 워크북' 내용을 기반으로 작성하였습니다.
'[UMC Ewha 5th] Server - SpringBoot' 카테고리의 다른 글
| [UMC Server] Chapter 7. JPA를 통한 엔티티 설계, 매핑 & 프로젝트 파일 구조 이해 (1) | 2023.11.22 |
|---|---|
| [UMC Server] Chapter 6. API URL의 설계 & 프로젝트 세팅 (0) | 2023.11.15 |
| [UMC Server] Chapter 4. Database 설계 & AWS RDS 설정 (1) | 2023.11.01 |
| [UMC Server] Chapter 3. Web Server & Web application Server(WAS), Reverse Proxy (1) | 2023.10.09 |
| [UMC Server] Chapter 2. AWS(VPC & Internet Gateway & EC2) (0) | 2023.10.04 |